도서 - SQL 레벨업 1
by choising
SQL 레벨업 ( ~ 62P)
1강 DBMS 아키텍처 개요
- 쿼리 평가 엔진
- 사용자로부터 입력받은 SQL 구문을 분석, 어떤 순서로 기억장치의 데이터에 접근할지 결정
- 이 때, 결정되는 계획을
실행 계획또는실행 플랜이라 부른다 - 이런 실행 계획에 기반을 둬서 데이터에 접근하는 방법을
접근 메서드(access method)
- 이 때, 결정되는 계획을
- 한 마디로 쿼리 평가 엔진은 계획을 세우고 실행하는 DBMS의 핵심기능을 담당하는 모듈
- 트랜잭션 매니저와 락 매니저
- 상용 시스템에서 복수의 사람이 동시에 DB에 접근해 사용한다
- 이 때 각각 처리는
트랜잭션이라는 단위로 관리된다 - 트랜잭선의 정합성을 유지하면서 실행 시키고, 필요한 경우 데이터에 락을 걸어 다른 요청을 대기시키는 역할을 한다
- 이 때 각각 처리는
2강 DBMS와 버퍼
기억 비용이라는 것은- 데이터를 저장하는데 소모되는 비용
- DBMS가 사용하는 대표적인 기억장치
- 하드디스크
- 메모리
- 버퍼(캐시)를 활용한 속도 향상
- SQL 구문의 실행 속도를 빠르게 만들기 위해 DBMS 는 일부라도 데이터를 메모리에 올린다
- 자주 접근하는 데이터를 메모리 위에 올려둔다면, 같은 SQL 구문을 실행한다고 해도 더 빠르다
- DBMS가 사용하는 메모리는 두 가지 종류
- 데이터 캐시
- 데이터 일부를 메모리에 유지
- 로그 버퍼
- DBMS는 갱신 SQL을 받았을 때, 로그 버퍼 위에 변경 정보를 보내고 이후에 디스크를 변경한다
- 데이터 캐시
- 메모리의 성질이 초래하는 트레이드오프
- 휘발성
- 로그 파일에 전달된 갱신정보가 DBMS가 장애로 다운될 때 사라져 버린다면 문제가 발생
- DBMS가 갱신을 비동기로 하게 되면 언제든 발생할 수 있는 문제
- 때문에, DBMS는
커밋이란 갱신처리를 확정(디스크에 동기 접근)- DBMS는 커밋 시점에 반드시 갱신 정보를 로그파일에 씀으로써 장애가 발생해도 정합성을 유지
- 디스크에 동기 처리 한다면 데이터의 정합성은 높아지지만 성능은 낮아진다
- 대부분의 DBMS에서 공통으로 데이터 캐시에 비해 로그 버퍼의 초깃값이 굉장히 작다.
- 그 이유는 기본적으로
검색을 메인으로 처리한다고 가정하기 때문 - 당연히 갱신이 많다면 로그 버퍼의 크기를 늘려주는 튜닝이 필요함
- 그 이유는 기본적으로
- 검색과 갱신 중에서 중요한 것을 정해야한다
- 메모리라는 비싼 희소 자원으로 모든 것을 커버하기에는 부족하므로 우선순위가 필요
- 추가적인 메모리 영역
워킹 메모리- 정렬 또는 해시 관련 처리에 사용되는 작업용 영역
- 정렬 : ORDER BY, 집합 연산, 윈도우 함수 등의 기능을 사용할 때 실행
- 해시 : 테이블의 결합(해시 결합)
- ex) 오라클의
PGA, PostgreSQL의워크 버퍼, MySQL의정렬 버퍼 - 만약, 이 영역이 다루려는 데이터 양보다 작아 부족해지는 경우가 생기면 대부분의 경우 저장소를 사용한다 (성능적으로 중요하다)
- 이 때 사용하는 영역의 이름은 오라클 TEMP Tablespace, MSSQL TEMPDB, PostgreSQL pgsql_tmp
- 저장소 위에 있으므로 당연히 접근 속도가 느리다
3강 DBMS와 실행 계획
-
DBMS의 쿼리 처리 흐름
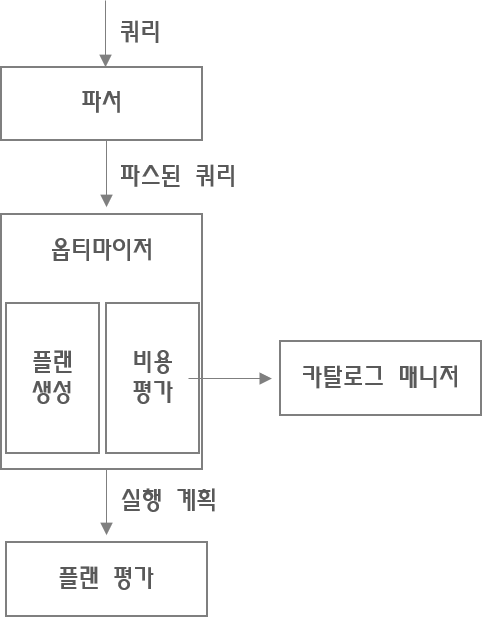
- Parser(파서)
- 구문 분석 역할
- Optimizer(옵티마이저)
- 한국 번역은
최적화 - 최적화의 대상이
실행 계획, DBMS 두뇌의 핵심 - 플랜 생성
- 인덱스 유무, 데이터 분산/편향 정도, DBMS 내부 매개변수 등 조건을 고려하여 선택 가능한 많은 실행계획 작성
- 비용 평가
- 이들의 비용을 연산
- 가장 낮은 비용의 실행계획을 택한다
- 한국 번역은
- Catalog Manager(카탈로그 매니저)
- 옵티마이저가 실행 계획을 세울 때 옵티마이저에 중요한 정보를 제공하는 역할
- 카탈로그
- DBMS 내부 정보를 모아놓은 테이블
- 테이블, 인덱스의 통계 정보가 저장
- 카탈로그 정보를
통계 정보라고 부르기도 한다
- Plan Evaluation(플랜 평가)
- 최적의 실행결과를 선택하는 것
옵티마이저와 통계 정보
-
플랜 선택을 옵티마이저에게 맡기는 경우, 실제로 최적의 플랜이 선택되지 않는 경우가 꽤 많다
-
대표적인 원인으로 통계정보가 부족한 경우
- 카탈로그에 포함되어 있는 통계정보는 아래와 같은 것들
- 각 테이블의 레코드 수
- 각 테이블의 필드 수와 필드의 크기
- 필드의 cardinality (값의 개수)
- 필드 값의 히스토그램 (분포정도)
- 필드 내부에 있는 Null 수
- 인덱스 정보
- 문제가 생기는 경우는 이러한 카탈로그 정보가 테이블 또는 인덱스의 실제와 일치하지 않을 때
- 테이블에 데이터 삽입/갱신/제거 시 카탈로그 정보가 갱신되지 않는다면
- 옵티마이저는 오래된 정보를 바탕으로 실행 계획을 세우게 된다
최적의 실행 계획이 작성되게 하려면
-
위처럼, 올바른 통계 정보가 모이는 것은 SQL 성능에 있어서 굉장히 중요한 문제
- 수동으로 갱신하는 것 뿐 아니라 DBMS 에 따라 갱신 전략에 차이가 있다.
- ex) Oracle 기본설정에서 정기적으로 통계 정보 갱신 Job 수행, MS SQL 갱신 처리가 수행되는 시점에 자동으로 통계 정보 갱신
- 통계 정보 갱신은 실행 비용이 굉장히 높은 작업
- 하지만 DBMS가 최적의 플랜을 선택하려면 꼭 필요한 조건이므로,
갱신 시점을 확실히 검토해야한다
- 하지만 DBMS가 최적의 플랜을 선택하려면 꼭 필요한 조건이므로,
4강 실행 계획이 SQL 구문의 성능을 결정
- SQL 구문 지연이 발생했을 때 가장 먼저
실행 계획을 살펴야 한다- DBMS 실행 계획 조사하는 명령 인터페이스
- Oracle : set autotrace traceonly
- MSSQL : SET SHOWPLAN_TEXT ON
- DB2 : EXPLAIN ALL WITH SNAPSHOT FOR SQL 구문
- MySQL : EXPLAIN EXTENDED SQL 구문
- DBMS 실행 계획 조사하는 명령 인터페이스
테이블 풀 스캔의 실행 계획
SELECT *
FROM Shops
- 실행 계획의 출력 포맷은 다르지만, 공통적으로 나타나는 부분
- 조작대상 객체
- 쉽게 생각하면 Table
- Table 이외에도 인덱스, 파티션, 시퀀스 처럼 SQL 구문으로 조작할 수 있는 모든 객체
- 객체제 대한 조작의 종류
- Seq Scan (순차적 접근), TABLE ACCESS FULL (테이블 데이터를 전부 읽기)
- 조작 대상이 되는 레코드 수
- 결합 또는 집약이 포함되면 1개의 SQL 구문이라도 여러 개의 조작이 수행된다
- 실제 SQL 구문 실행 시점의 테이블 레코드 수와 차이가 있을 수 있다
카탈로그 매니저로부터 얻은 통계 정보 이므로
- 조작대상 객체
인덱스 스캔의 실행 계획
SELECT *
FROM Shops
WHERE shop_id = '00050'
- 조작 대상이 되는 레코드 수
- Rows : 1
- 접근 대상 객체와 조작
- Index Scan, INDEX UNIQUE SCAN (인덱스를 사용한 스캔)
- 데이터의 양이 많을 수록 인덱스 스캔은 빨라진다
- 인덱스를 사용할 때 활용되는 B-tree가 모집합의 데이터 양에 따라 대수 함수(로그 함수 O(log n))적으로 처리 비용이 늘어나기 때문
간단한 테이블 결합의 실행 계획
- SQL에서 지연이 일어나는 경우는 대부분 JOIN과 관련이 있다
SELECT shop_name
FROM Shops S INNER JOIN Reservations R
ON S.shop_id = R.shop_id;
- JOIN 알고리즘
- Nested Loops
- 가장 간단한 JOIN 알고리즘
- 한 쪽 테이블을 읽으면서 레코드 하나마다 결합 조건에 맞는 레코드를 다른 쪽 테이블에서 찾는 방식
- 2중 반복문으로 구현되므로 중첩 반복 이라는 이름이 붙었다
- Sort Merge
- 결합 키로 레코드를 정렬하고 순차적으로 두 개의 테이블을 결합하는 방법
- JOIN 전에 전처리로 정렬을 수행하는데, 이 때
워킹 메모리를 사용한다.
- Hash
- 결합 키 값을 해시값으로 맵핑
- 해시 테이블을 만들어야 하므로 이 또한
워킹 메모리영역이 필요하다
- Nested Loops
5강 실행 계획의 중요성
- 옵티마이저는 꽤 우수하나 완벽하지는 않다
- 실행 계획을 변경하는
튜닝이 필요하다- 그러기 위해서는 어떠한 선택지가 있는 지 알아야 한다
- 또한 SQL 구문들이 어떠한 access path(접근 경로)로 데이터를 검색하는 지 알아야 한다
- 테이블 설정의 효율성도 알아야 하며, 어떤 SQL 구문의 실행계획을 예측할 수 있어야 한다
Subscribe via RSS